Cet article est une traduction de The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) par Jay Alamar.
L’année 2018 a été un point d’inflexion pour les modèles de l’apprentissage automatique qui gèrent du texte (ou, plus précisément, le Natural Language Processing – NLP en abrégé). Notre compréhension conceptuelle de la meilleure façon de représenter des mots et des phrases pour capturer les significations et relations est en évolution rapide. De plus, la communauté NLP publie des composants très puissants que l’on peut télécharger gratuitement pour utiliser dans nos propres pipelines et modèles. (On a appelé ce moment dans le domaine “le moment ImageNet de NLP”, une référence aux développements similaires dans le domaine de computer vision il y a quelques années qui ont rapidement accéléré le progrès dans ce domaine-là.)
| (ULM-FiT n’a rien à voir avec Macaron le glouton, le Cookie Monster. Mais j’avais du mal à choisir quelque chose d’autre comme image… |
Un développement récent est la sortie de BERT, un événement décrit comme le début d’une nouvelle époque dans le NLP. BERT est un modèle qui battu plusieurs records pour la gestion de tâches basées sur le langage. Bientôt après la sortie de l’article décrivant le modèle, l’équipe a sortie le code de manière open-source, et a publié aussi des versions du modèle déjà entraînés sur des données massives. Ceci est un énorme développement, puisqu’il permet à qui que ce soit qui construit un modèle lié au langage d’utiliser cette pile électrique comme composant déjà disponible – permettant la conservation du temps, de l’énergie, de la connaissance, et des ressources qui auraient été dépensés dans l’entraînement d’un tel modèle à partir de rien.
| Les deux étapes du développement de BERT. On peut télécharger le modèle déjà entraîné en étape 1 (entraîné sur les données non-annotées, et comme ça on n’a qu’à faire du fine-tuning en étape 2. [Image de livre] |
{kind=link}
BERT continue plusieurs idées intelligentes récentes de la communauté NLP – y compris le Semi-supervised Sequence Learning (par Andrew Dai et Quoc Le), ELMo (par [Matthew Peters]9https://twitter.com/mattthemathman) et des chercheurs de AI2 et UW CSE), ULMFiT (par le fondateur de fast.ai Jeremy Howard et Sebastian Ruder), le OpenAI transformer (par des chercheurs OpenAI Radford, Narasimhan, Salimans, et Sutskever), et le transformer (Vaswani et al.).
Exemple: une classification de phrase
La méthode la plus directe d’utiliser BERT, c’est de l’utiliser pour classifier un seul morceau de texte. Ce modèle ressemblerait à ça:
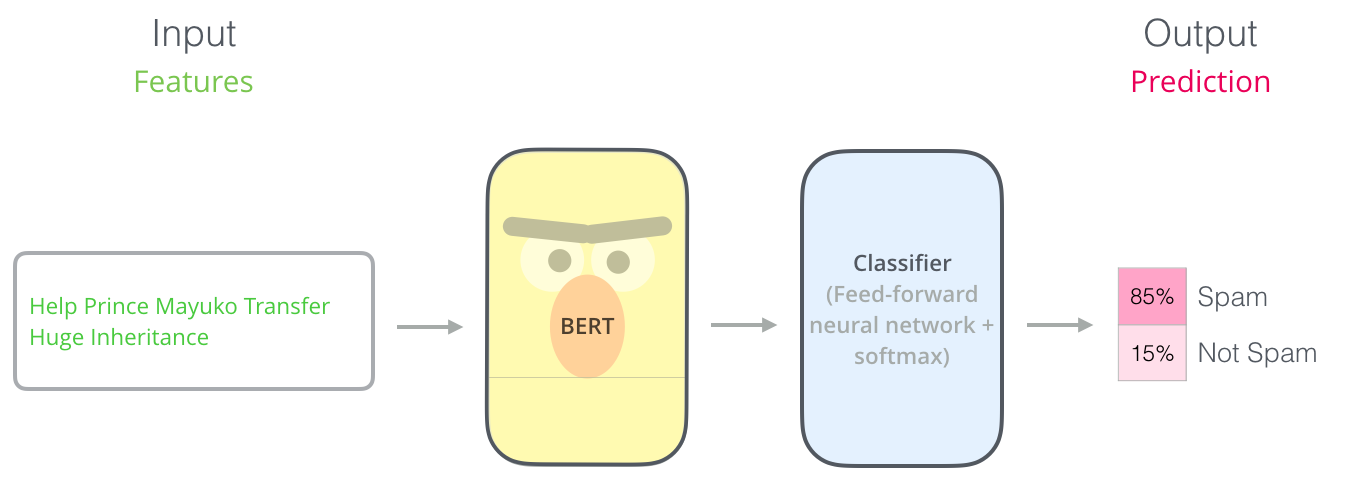
Pour entraîner un tel modèle, on doit entraîner principalement le classificateur, avec des changements minimes comme conséquence au modèle BERT. Ce processus d’entraînement s’appelle du fine-tuning, et il a des racines dans le Semi-supervised Sequence Learning et ULMFiT.
Pour ceux qui ne connaissent pas bien ce sujet, puisque l’on parle des classificateurs, on est dans le domaine de l’apprentissage automatique supervisé. Ça veut dire que l’on aurait besoin des données étiquettées pour entraîner un modèle. Pour cet exemple d’un classificateur de spam, les données étiquettées serait une liste de messages courriels et leurs étiquettes (“spam” ou “pas spam” pour chaque message).

Il y a beaucoup d’autres exemples de cas d’utilisation pour un tel modèle, y compris:
- L’analyse de sentiment
- À l’entrée: une critique d’un film ou d’un produit. À la sortie: est-ce que la critique est positive ou négative?
- Exemple de données: SST
- La vérification de faits
- À l’entrée: une phrase. À la sortie: “affirmation” ou “pas affirmation”
- Un exemple plus ambitieux/futuriste:
- À l’entrée: une phrase d’affirmation. À la sortie: “vrai” ou “faux”
- Full Fact est un organisme qui construit des outils automatiques pour la vérification de faits pour le public. Une partie de leur pipeline est un classificateur qui lit des articles d’actualité et que détecte des affirmations (ça classifie le texte comme “affirmation” ou “pas affirmation”), qui peuvent être vérifiées plus tard (maintenant par les êtres humains, plus tard peut-être par l’apprentissage automatique).
- Vidéo: Sentence embeddings for automated factchecking - Lev Konstantinovskiy.
L’architecture du modèle
Maintenant que l’on a un exemple d’utilisation de BERT sous la main, regardons de plus près comment ça marche.

L’article présente deux tailles de modèle pour BERT:
- BERT BASE – celui-ci est comparable en taille à l’OpenAI Transformer; on peut ainsi comparer leurs performances
- BERT LARGE – un ridiculement grand modèle qui a donné les résultats de pointe rapportés dans l’article
BERT est, en gros, une pile d’encodeur entraînée du transformer. C’est un bon moment de vous diriger vers l’article précédent, Le transformer illustré, qui explique le modèle transformer – un concept de base pour BERT et les concepts suivants.
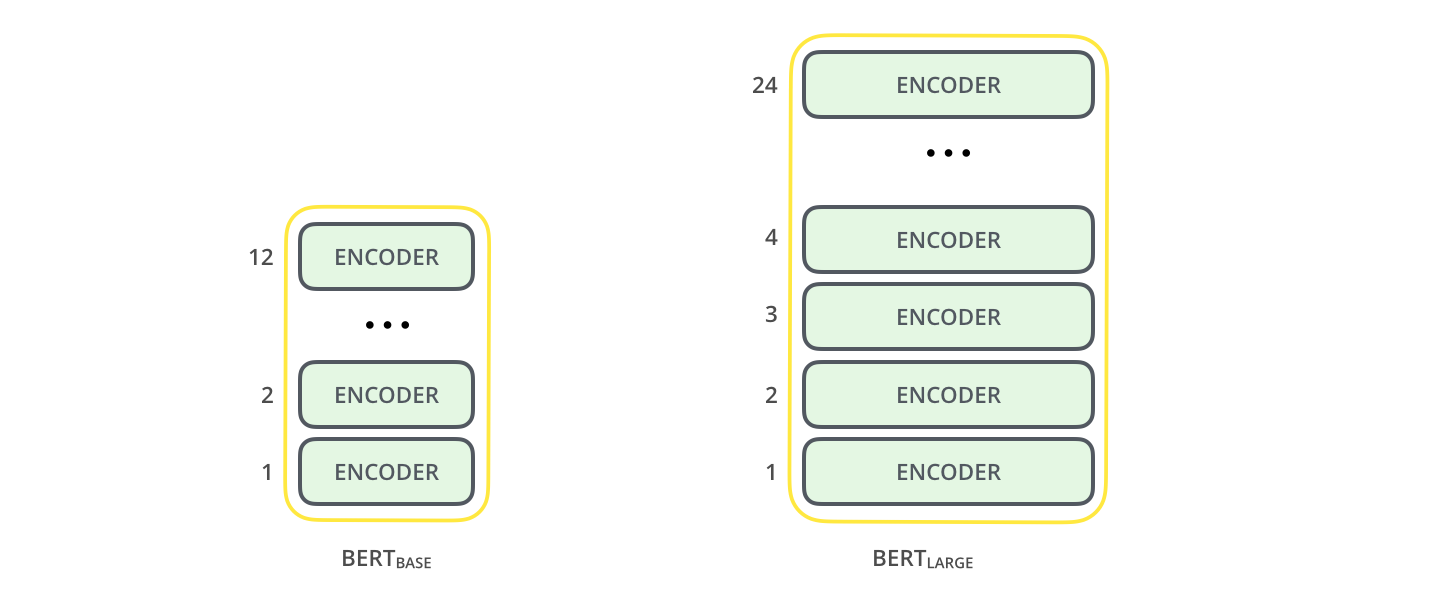
Les deux tailles de modèle de BERT ont un grand numéro de couches d’encodeur (que l’article appelle des blocs de transformer) – il y en a douze pour la version BASE, et vingt-quatre pour la version LARGE. Ils ont aussi des plus grands réseaux feed-forward (768 et 1024 unités cachées respectivement), et plus de têtes d’attention (12 et 16 respectivement) que la configuration de défaut dans l’implémentation de référence du transformer dans l’article original (6 couches d’encodeur, 512 unités cachées, et 8 têtes d’attention).
À l’entrée du modèle
Le premier token à l’entrée est un token spécial, [CLS], pour des raisons qui vont s’éclaircir plus tard. [CLS] ici signifie “classification”.
Comme l’encodeur “vanille” du transformer, BERT prend une séquence de mots à l’entrée, qui coulent vers le haut de la pile. Chaque couche applique une self-attention et passe ses résultats dans un réseau feed-forward avant de les donner au prochain encodeur.
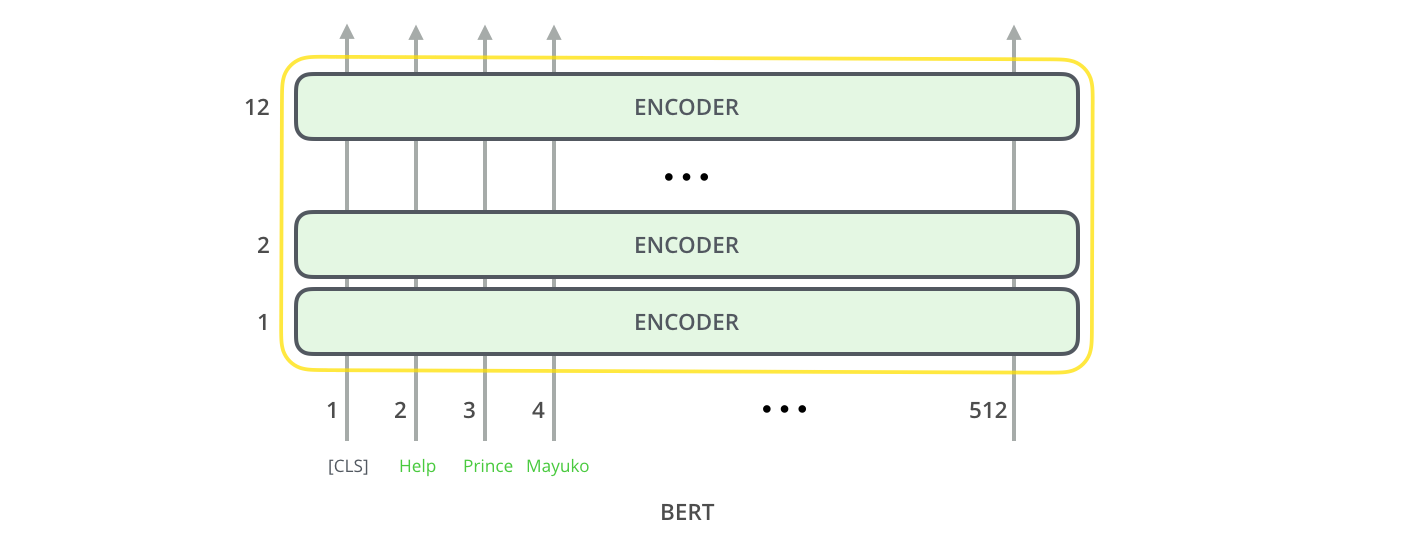
En termes d’architecture, ce que l’on voit est identique au transformer jusqu’à ce point (à part la taille, ce qui est simplement une configuration que l’on peut modifier). C’est à la sortie que l’on commence à voir de la divergence.
À la sortie du modèle
Chaque position donne à la sortie un vecteur de taille hidden_size (768 dans BERT BASE). Pour l’exemple de classification de phrase que l’on a vu plus tôt, on se concentre uniquement sur la sortie de la première position (que l’on a passé le token spécial [CLS]).
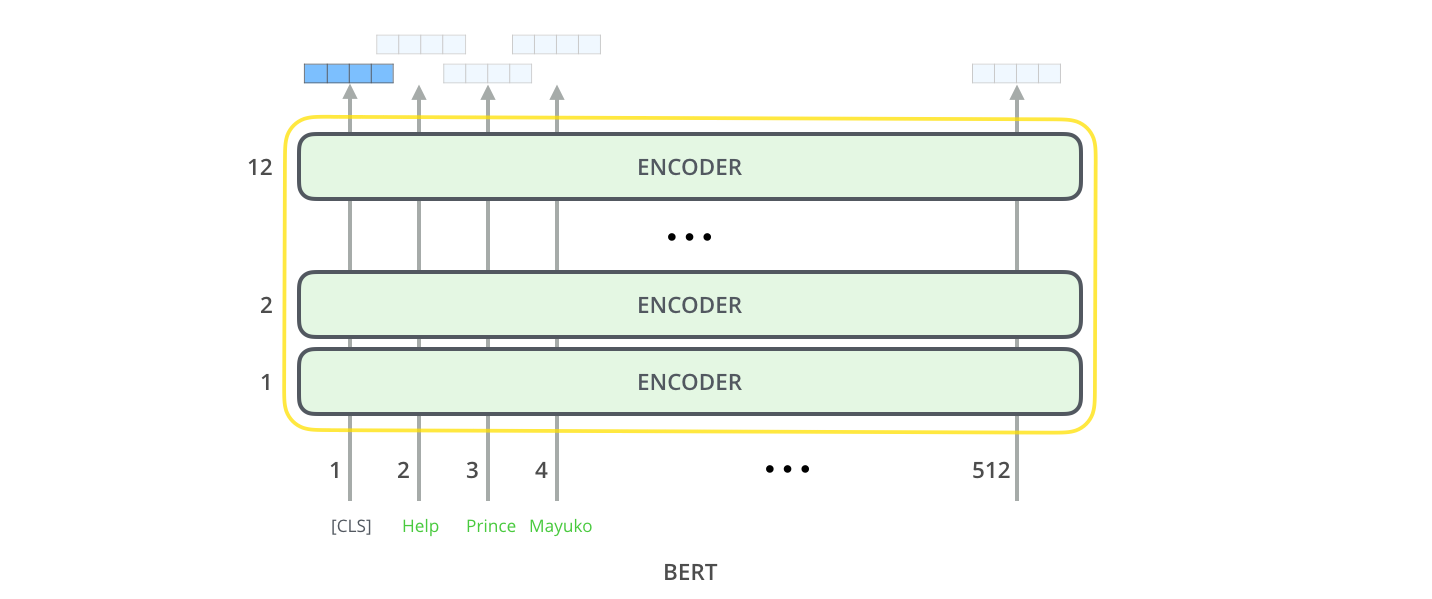
Ce vecteur peut maintenant être utilisé comme l’entrée d’un classificateur de notre choix. Cet article donne de bons resultats en utilisant seulement un réseau d’une seule couche comme classificateur.
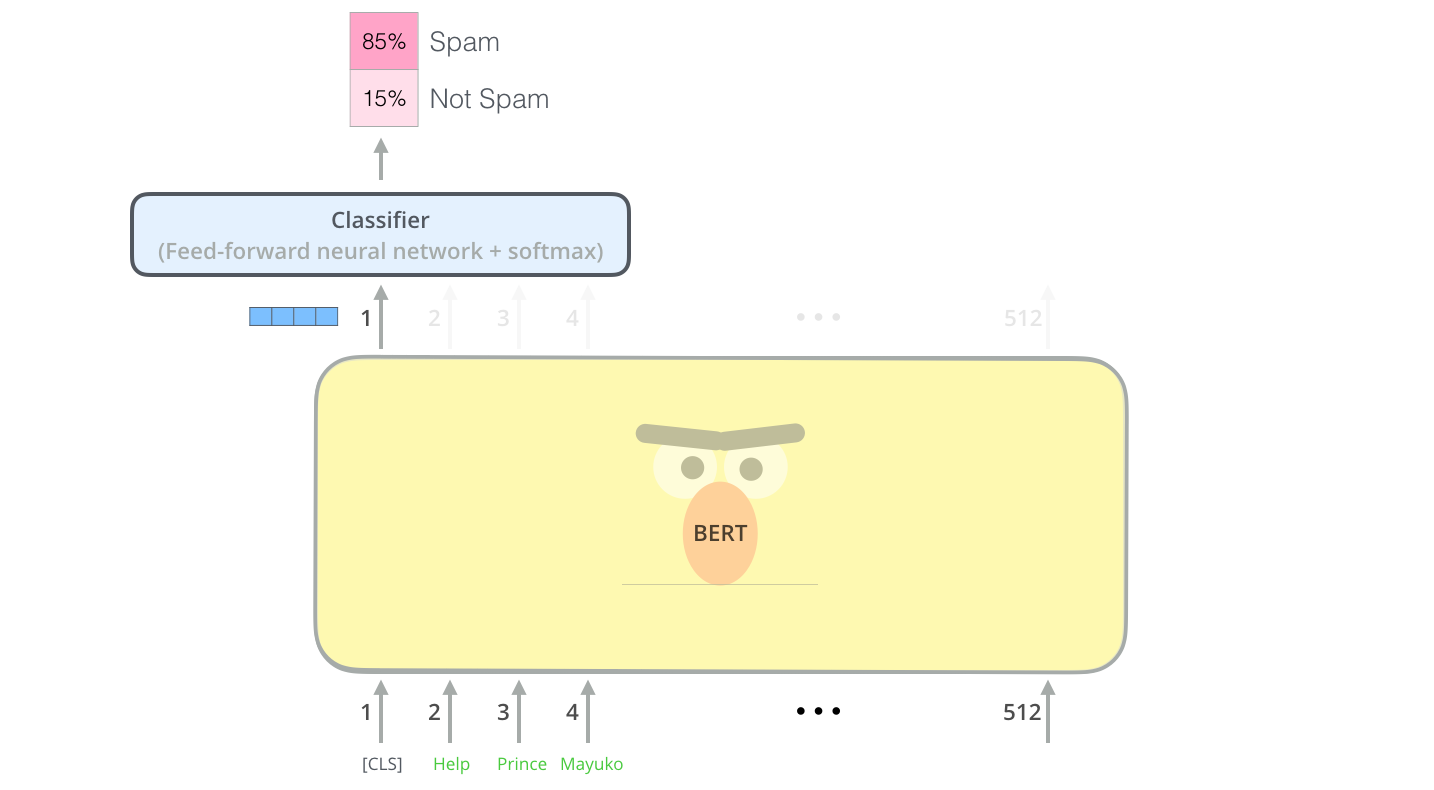
Si l’on a plus d’étiquettes (par exemple, si notre service courriel peut étiquetter les messages comme “spam”, “pas spam”, “social” et “promotion”), on peut simplement adjuster le réseau classificateur pour avoir plus de neurones à la sortie qui vont ensuite passer dans le softmax.
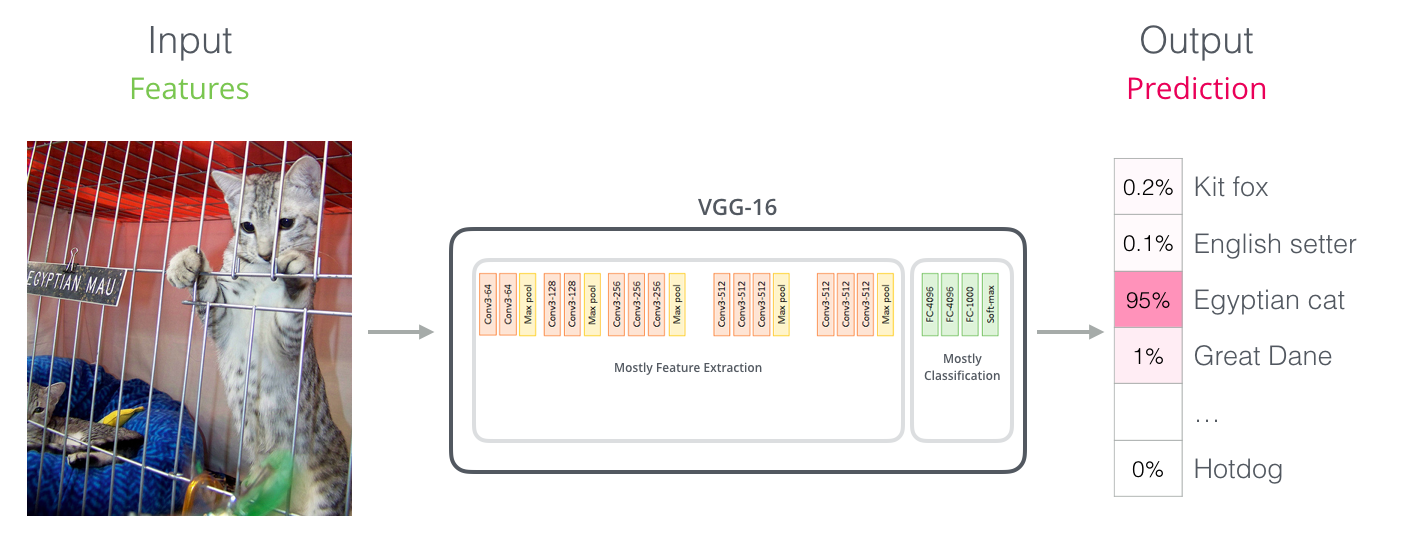
Des parallèles avec les réseaux convolutionnels
Pour ceux et celles avec la connaissance en computer vision, cette échange de vecteurs devrait vous rappeller de ce qui arrive entre la partie convolutionnelle d’un réseau comme VGGNet et la partie fully-connected de classification à la fin du réseau.
Un nouvel âge d’embedding
Ces nouveaux développements portent avec eux un changement de la manière dont les mots sont encodés. Jusqu’à maintenant, les embeddings de mots ont été une force majeure dans la gestion des modèles NLP. Des méthodes comme Word2Vec et GloVE ont été largement utilisés pour ces tâches. Revoyons comment ces méthodes s’utilisent avant de voir ce qui a changé.
Résumé d’embedding
Afin que des mots puissent être traités par des modèles d’apprentissage automatique, ils ont besoin d’une représentation numérique que ces modèles peuvent utiliser dans leur calcul. Word2Vec a montré que l’on peut utiliser un vecteur (une liste de chiffres) pour représenter les mots d’une manière qui capture les relations sémantiques (c’est-à-dire, liées à la signifiance). Ça pourrait inclure la capacité de dire si les mots sont similaires, opposés, ou qu’un pair de mots comme Stockholm et Suède ont la même relation entre eux que Cairo et Egypte. On peut aussi capturer les relations syntaxiques (basées sur la grammaire), e.g. la relation entre avait et a est pareil que la relation entre était et est.
Le domaine s’est rapidement rendu compte que c’est une bonne idée d’utiliser des embeddings déjà entraînés sur des grandes quantités de données de texte, au lieu de les entraîné en même temps que le reste du modèle, sur des données souvent beaucoup plus petites. Alors il est devenu possible de télécharger une liste de mots et leurs embeddings générés par le pré-entraînement avec Word2Vec ou GloVE. Voilà un exemple de l’embedding GloVE du mot stick (avec une taille de vecteur de 200):
 |
| L’embedding du mot stick – un vecteur de 200 flottants (arrondis à deux décimaux). Il continue jusqu’à 200 valeurs. |
Puisqu’ils sont larges et plein de chiffres, j’utilise la forme de base suivanate dans mes figures pour montrer des vecteurs:

ELMo: Le contexte importe
Si l’on utilise cette représentation GloVE, le mot stick serait représenté par ce vecteur – peu importe le contexte. “Attendez une minute,” ont dit beaucoup de chercheurs en NLP (Peters et. al., 2017, McCann et. al., 2017, et encore une fois Peters et. al., 2018 dans l’article ELMo), “le mot stick a beaucoup de significations possibles, en fonction d’où il s’utilise. Pourquoi ne pas lui donner un embedding basé sur le contexte où il se trouve? Ça capturait non seulement la signification du mot en contexte, mais aussi des autres informations contextuelles.” Et donc, les embeddings contextualisés sont nés.
 |
| Des embeddings contextualisés de mots peuvent donner aux mots des embeddings différents en fonction de la signification en contexte dans la phrase. RIP Robin Williams. |
Au lieu d’utiliser unembedding figé pour chaque mot, ELMo regarde la phrase entière avant d’assigner un embedding à chaque mot. Il utilise un LSTM bidirectionnel entraîné sur une tâche spécifique pour pouvoir créer ces embeddings.
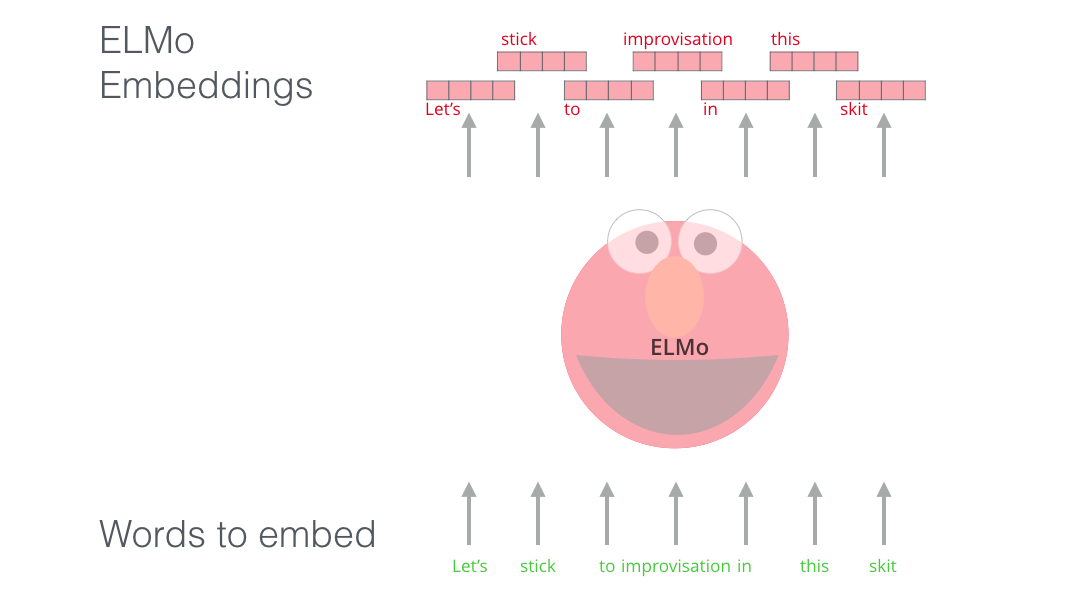
ELMo représentait une étape significative vers le pré-entraînement dans le contexte du NLP. Le LSTM de ELMo serait entraîné sur des données massives de la même langue que nos données, puis on peut l’utiliser comme composant des autres modèles qui doivent gérer du langage.
Quel est le secret d’ELMo?
ELMo a gagné sa compréhension de langage de son entraînement, où il devait prédire le prochain mot dans une séquence de mots – cette tâche s’appelle du language modeling. C’est pratique parce que l’on a des quantités massives de données texte, et un modèle peut apprendre à partir de ça, sans étiquettes.
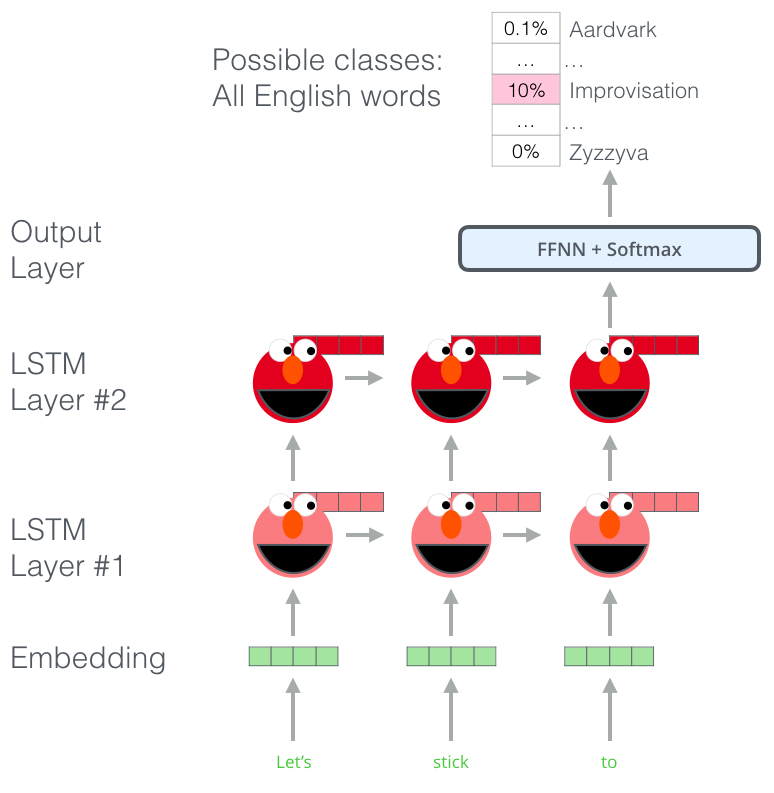 |
| Une étape dans le processus de pré-entraînement d’ELMo. Étant donné Let’s stick to à l’entrée, prédisons le prochain mot le plus probable – une tâche de language modeling. Quand il est entraîné sur beaucoup de données, le modèle commence à apprendre les motifs dans le langage. Il est peu probable qu’il devine le mot prochain dans cet exemple. De manière plus réaliste, après un mot comme hang, il va assigner une probablité plus haute à un mot comme out (pour donner hang out en anglais, un mot composé), plutôt qu’à camera (un mot totalement non-lié). |
On peut voir l’état caché de chaque étape du LSTM déroulé derrière la tête d’Elmo. Ils deviennent utiles dans le processus d’embedding après ce pré-entraînement.
En fait, ELMo va une étape plus loin en entraînant un LSTM bidirectionnel – donc son modèle de langue n’a qu’une idée du mot prochain, mais aussi du mot précédent.
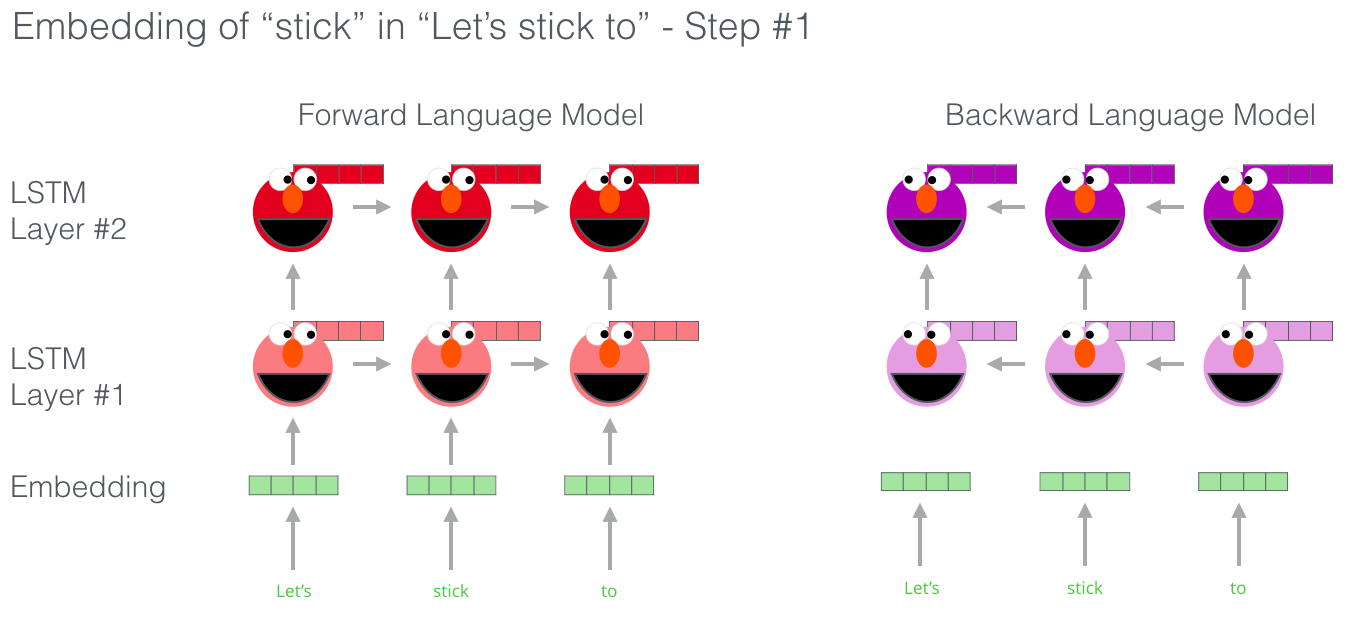 |
| Des bons diapositifs sur ELMo |
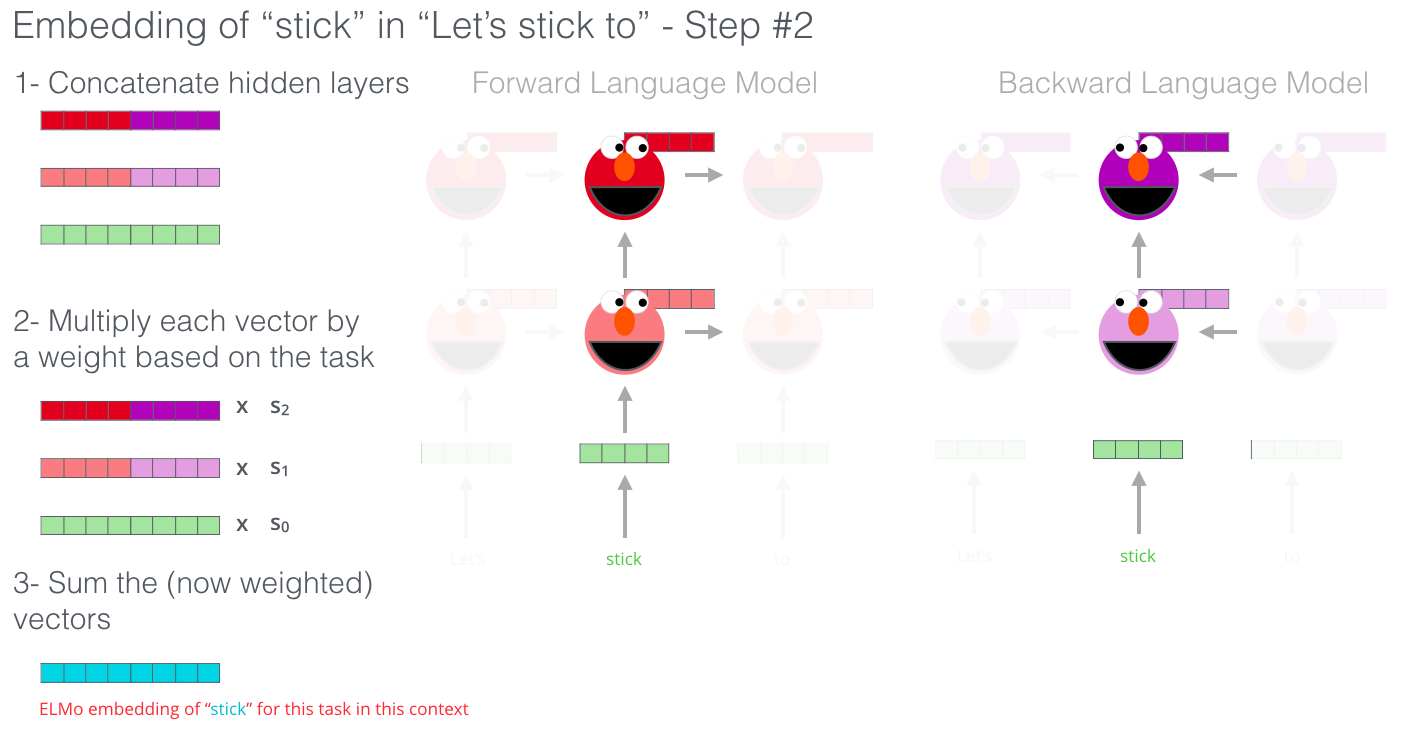
ELMo produit l’embedding contextualisé en groupant les états cachés (et l’embedding initial) d’une certaine manière (une concatenation suivie par une somme pondérée).
ULM-FiT: l’intégration du transfer learning en NLP
ULM-FiT a introduit des méthodes efficaces pour utiliser beaucoup de ce que le modèle apprend pendant le pré-entraînement – plus que seulement les embeddings, et plus que seulement les embeddings contextualisés. ULM-FiT a introduit un modèle de langue et un processus pour faire du fine-tuning sur ce modèle de langue pour plusieurs tâches.
Enfin, le NLP a eu une manière de faire du transfer learning avec autant d’efficacité que le computer vision.
Le transformer: au-delà des LSTM
La sortie de l’article sur les transformers et son code, ainsi que ses resultats sur des tâches comme la machine translation, ont poussé quelques-uns dans le domaine de penser aux transformers comme remplaçant les LSTM. Cette idée a été renforcée par le fait que les transformers gèrent des dépendances de long terme mieux que les LSTM.
La structure encodeur-decodeur du transformer l’a rendu idéal pour la machine translation. Mais comment peut-on l’utiliser pour une classification de phrase? Comment peut-on l’utiliser pour pré-entraîner un modèle de langue qui pourrait être adjusté par le fine-tuning pour des autres tâches? (Le domaine appelle ce genre de tâche supervisée qui utilise un modèle ou un composant pré-entraîné une tâche en aval.)
OpenAI Transformer: pré-entraîner un décodeur de transformer pour du language modeling
Il se trouve que l’on n’a pas besoin d’un transformer entier pour adopter le transfer learning et un language model capable de recevoir du fine-tuning pour des tâches de NLP. On peut partir simplement avec le décodeur du transformer. Le décodeur est un bon choix parce qu’il est un choix naturel pour le language modeling (la prédiction du mot suivant), puisqu’il est fait pour masquer les tokens futurs – un comportement de valeur quand on génère une traduction un mot à la fois.
| L’OpenAI Transformer se compose de la pile décodeur du transformer. |
Le modèle empile douze couches de décodeur. Puisqu’il n’y a pas d’encodeur dans cette configuration, ces couches de décodeur n’auraient pas la sous-couche d’attention encodeur-décodeur que l’on voit dans les couches de décodeur d’un transformer “vanille”. Il y aurait encore la couche de self-attention, pourtant, en verson masquée pour qu’elle ne regarde pas les tokens futurs.
Avec cette structure, on peut continuer à l’entraînement du modèle sur la même tâche de language modeling: prédisons le mot prochain, en utilisant des données massives sans étiquettes. Tout simplement, on jète le texte de 7,000 livres dans le modèle pour qu’il apprenne! Les livres sont idéaux pour ce genre de tâche parce que ça permet au modèle d’apprendre l’association entre les informations liées même si elles sont séparées par beaucoup de texte. Cet effet n’est pas possible quand on entraîne avec des Tweets ou des articles.
| L’OpenAI Transformer est maintenant prêt à être entraîné à prédire le prochain mot sur des données de 7,000 livres. |
Transfer learning aux tâches en aval
Maintenant que l’OpenAI Transformer est pré-entraîné et que ses couches ont été adjustées pour gérer du langage de manière raisonable, on peut commencer à l’utiliser pour des tâches en aval. Regardons d’abord une classification de phrase (on veut classifier un courriel comme “spam” ou “pas spam”):
| Comment utiliser un OpenAI Transformer pré-entraîné pour la classification de phrase |
L’article OpenAI expose les grandes lignes de plusieurs transformations à l’entrée pour gérer les données d’entrée de plusieurs sortes de tâches. L’image suivant de l’article montre les structures des modèles et les transformations d’entrée pour faire des tâches différentes.
![]()
C’est astucieux, n’est-ce pas?
BERT: des décodeurs aux encodeurs
L’OpenAI Transformer nous a donné un modèle pré-entraîné basé sur le transformer sur lequel on peut faire du fine-tuning. Mais on a manqué quelque chose dans cette transition des LSTM aux transformers. Le modèle de langue de ELMo était bidirectionnel, mais l’OpenAI Transformer n’entraîne qu’un language model unidirectionnel. Pourrait-on construire un modèle basé sur un transformer dont le language model regarde en avant et en arrière (dans le jargon téchnique – qui est conditionné sur le contexte gauche et droit)?
“Vous verrez bien,” a repliqué BERT.
Un language model masqué
“On va utiliser des encodeurs du transformer,” a dit BERT.
“C’est fou!” a repliqué Ernie. “Tout le monde sait que le conditionnement bidirectionnel permettrait à chaque mot de se voir de manière indirecte dans un contexte aux multiples couches.”
“On va utiliser des masques,” a dit BERT avec confiance.
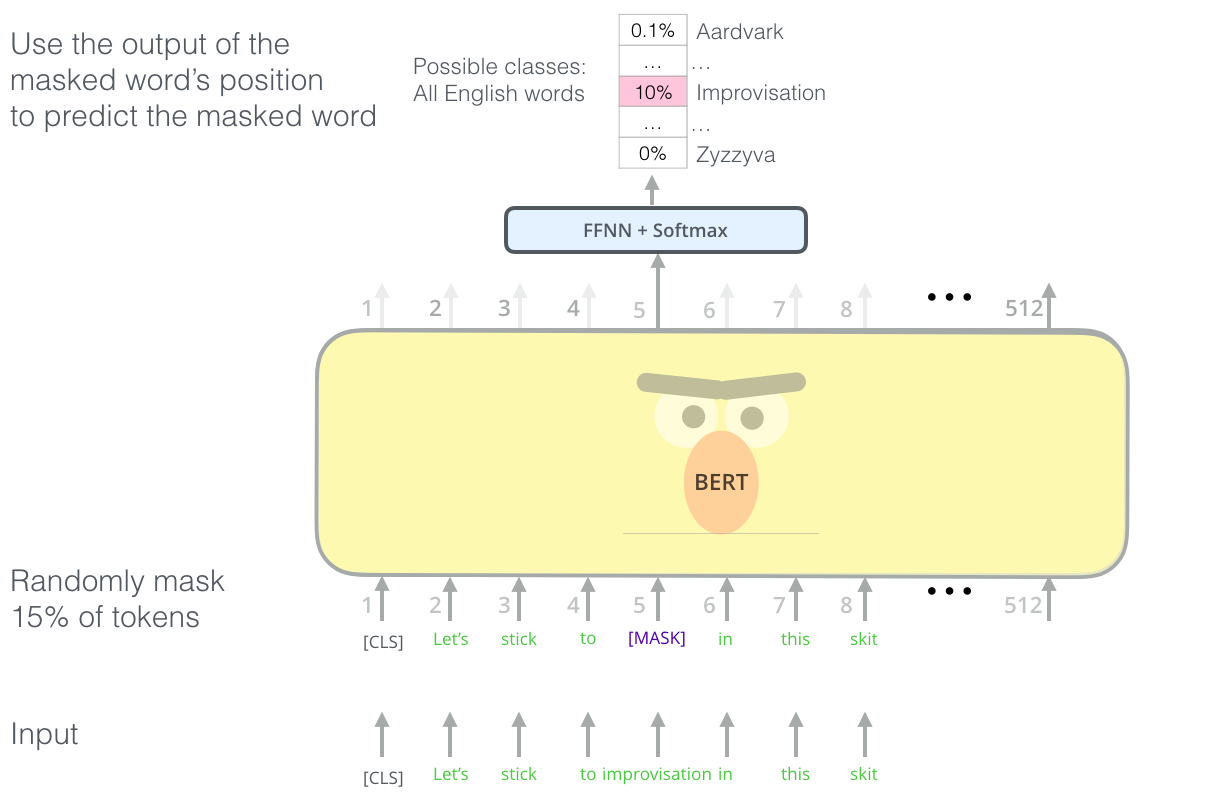 |
| La tâche astucieuse du language modeling de BERT met un masque sur 15% de mots à l’entrée, et demande au modèle de prédire le mot qui manque. |
Trouver la bonne tâche pour entraîner une pile d’encodeur de transformer est un problème complèxe que BERT résout en adoptant un concept de language model masqué, tiré de la littérature précédente (où ça s’appelle une tâche de Cloze).
En addition à masquer 15% de l’entrée, BERT mêle les choses un peu pour améliorer le fine-tuning plus tard. Quelquefois, il remplace de manière aléatoire un mot par un autre mot et il demande au modèle de prédire le bon mot dans cette position.
Des tâches de deux phrases
Si vous montez pour regarder les transformations d’entrée de l’OpenAI Transformer pour gérer des tâches différentes, vous remarquerez que quelques tâches exigent que le modèle dise quelque chose d’intelligent à propos de deux phrases (e.g. est-ce qu’elles sont simplement des paraphrases l’une de l’autre? Étant donnée une page Wikipedia comme entrée, et une question à propos de la page comme une autre entrée, est-ce que l’on peut répondre à cette question?)
Pour améliorer la performance de BERT sur les relations entre des multiples phrases, la tâche de pré-entraînement inclut une autre tâche: étant deux phrases (A et B), est-ce qu’il est probable que B suit A, ou pas?
 |
| La deuxième tâche du pré-entraînement de BERT est une tâche de classification de deux phrases. La tokenization dans cette figure est en fait sur-simplifié, puisque BERT utilise en réalité des WordPieces comme token plutôt que les mots en tant que tels – alors, quelques mots sont décomposés en plus petits morceaux. |
Des modèles spécifiques aux tâches
L’article BERT montre plusieurs manières d’utiliser BERT pour des tâches différentes.
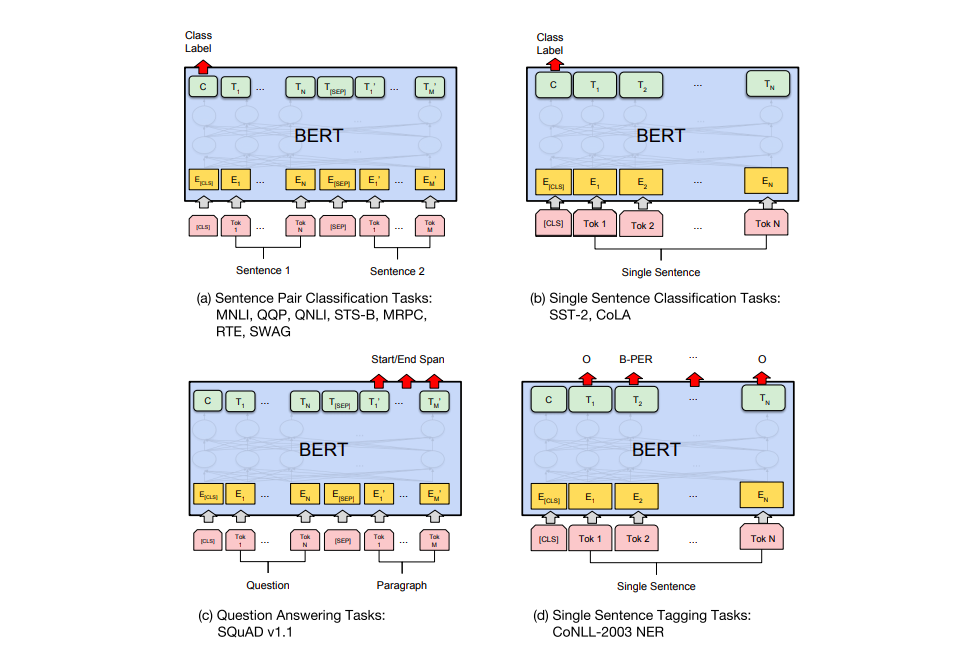
BERT pour l’extraction de feature
L’approche fine-tuning n’est pas la seule manière d’utiliser BERT. Exactement comme ELMo, on peut utiliser le BERT pré-entraîné pour créer des embeddings contextualisés. Ensuite, on peut donner ces embeddings au modèle existant. L’article montre que cette approche donne des résultats qui ne sont pas beacoup pires que l’approche fine-tuning sur une tâche telle que le named-entity recognition (la reconnaissance des entités).
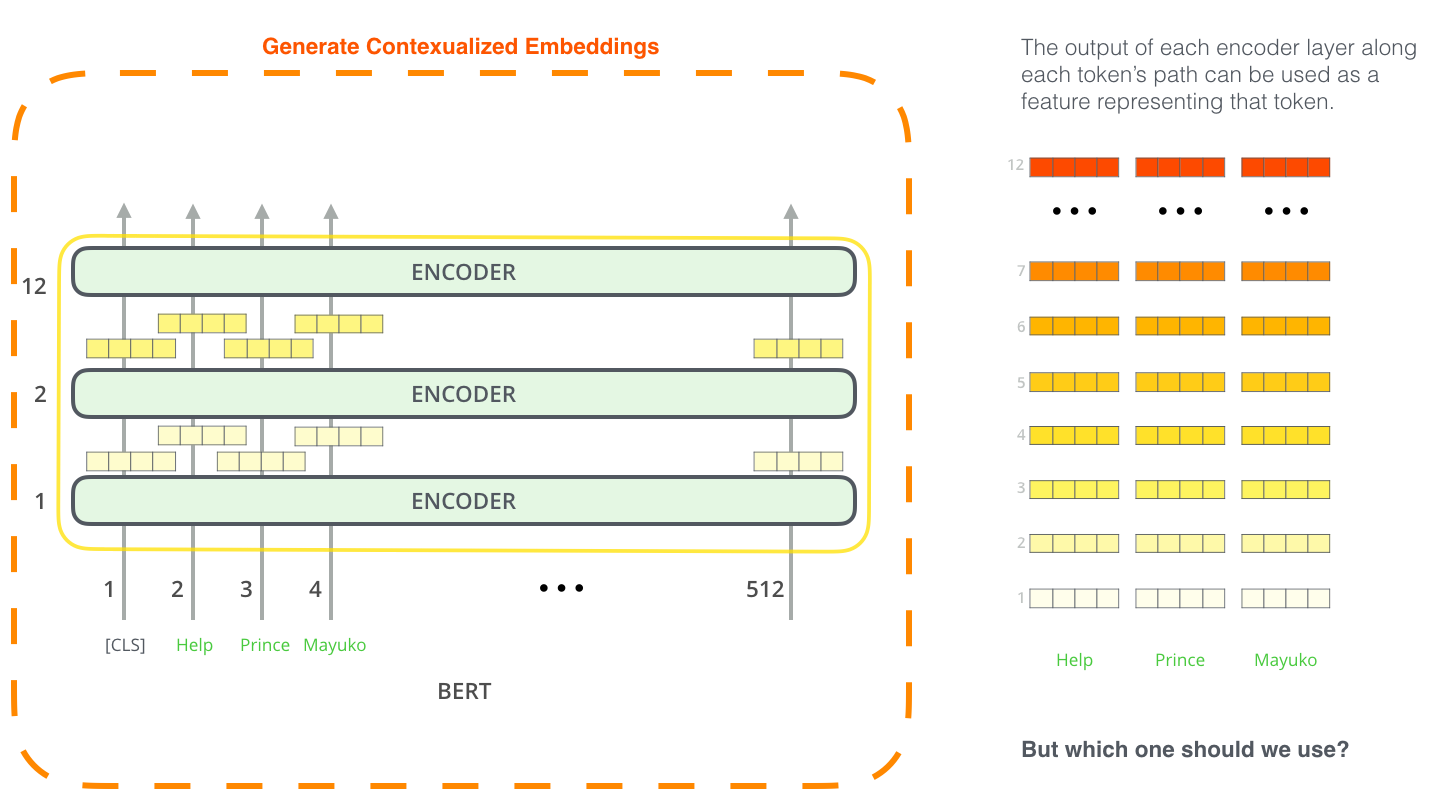
Quel vecteur fonctionne le mieux comme embedding contextualisé? Je pense qu’il dépendrait de la tâche. L’article examine six choix (en comparaison avec le modèle fine-tune qui a donné un score de 96.4):
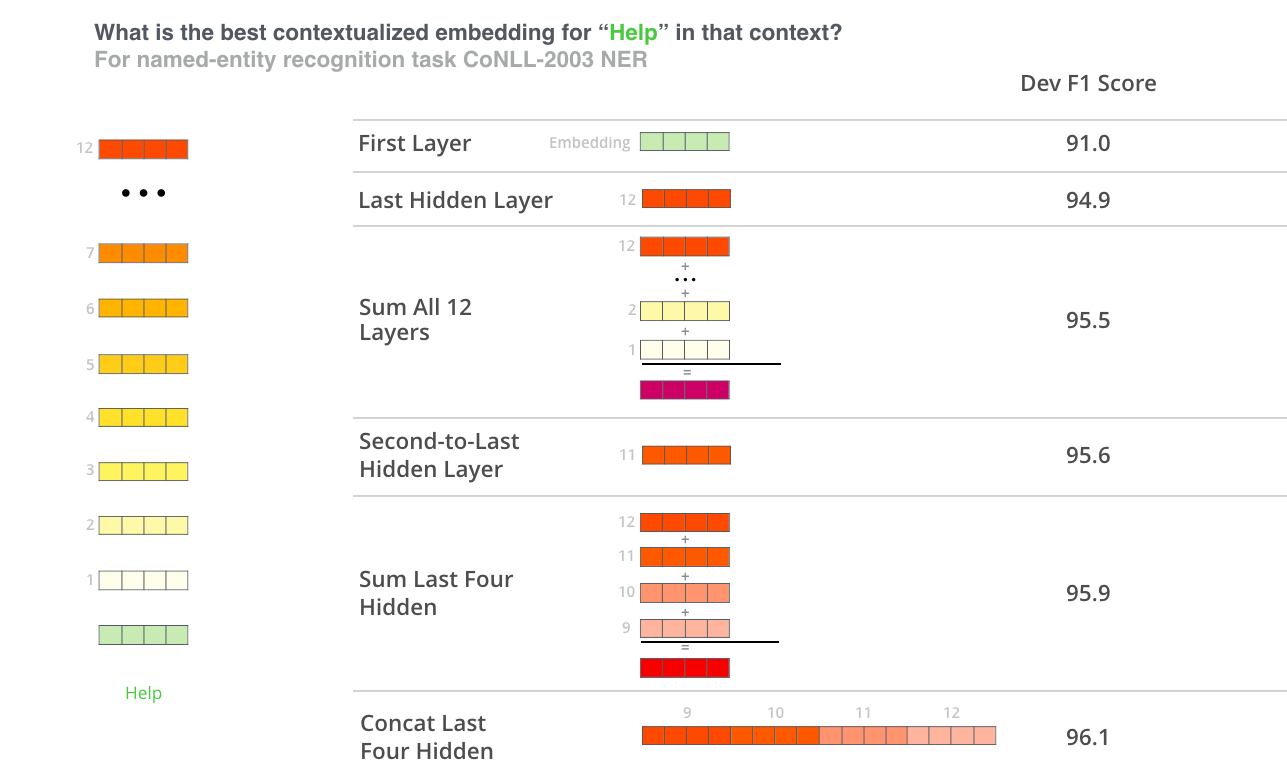
Faites un tour avec BERT
La meilleure façon d’essayer BERT est via le notebook BERT FineTuning with Cloud TPUs de Google Colab. Si vous n’avez pas encore utilisé des Cloud TPU, c’est aussi un bon point de départ pour les essayer aussi, vu que le code BERT fonctionne sur TPU, CPU, et GPU.
La prochaine étape serait de regarder le code de BERT:
-
Le modèle se construit dans modeling.py (
class BertModel) et c’est plus ou moins identique à un encodeur de transformer “vanille”. -
run_classifier.py est un exemplaire du processus fine-tuning. Il construit aussi la couche de classification pour le modèle supervisé. Si vous voulez construire votre propre classificateur, examine la méthode
create_model()dans ce fichier. -
Plusieurs modèles pré-entraînés sont disponibles à télécharger. Ils comprennent BERT BASE et BERT LARGE, ainsi que plusieurs langues y compris l’anglais, le chinois, et un modèle multilingue de 102 langues entraîné sur Wikipedia.
-
BERT ne regarde pas les mots entiers comme token. Plutôt, il regarde les WordPieces. tokenization.py est le tokenizer qui transforme les mots en WordPieces appropriés pour BERT.
Vous pouvez aussi regarder l’implémentation PyTorch de BERT. Le library AllenNLP utilise cette implémentation pour permettre l’utilisation des embeddings BERT avec n’importe quel modèle.
Remerciments
Merci à Jacob Devlin, Matt Gardner, Kenton Lee, Mark Neumann, et Matthew Peters pour avoir donné du feedback sur les versions initiales de cet article.